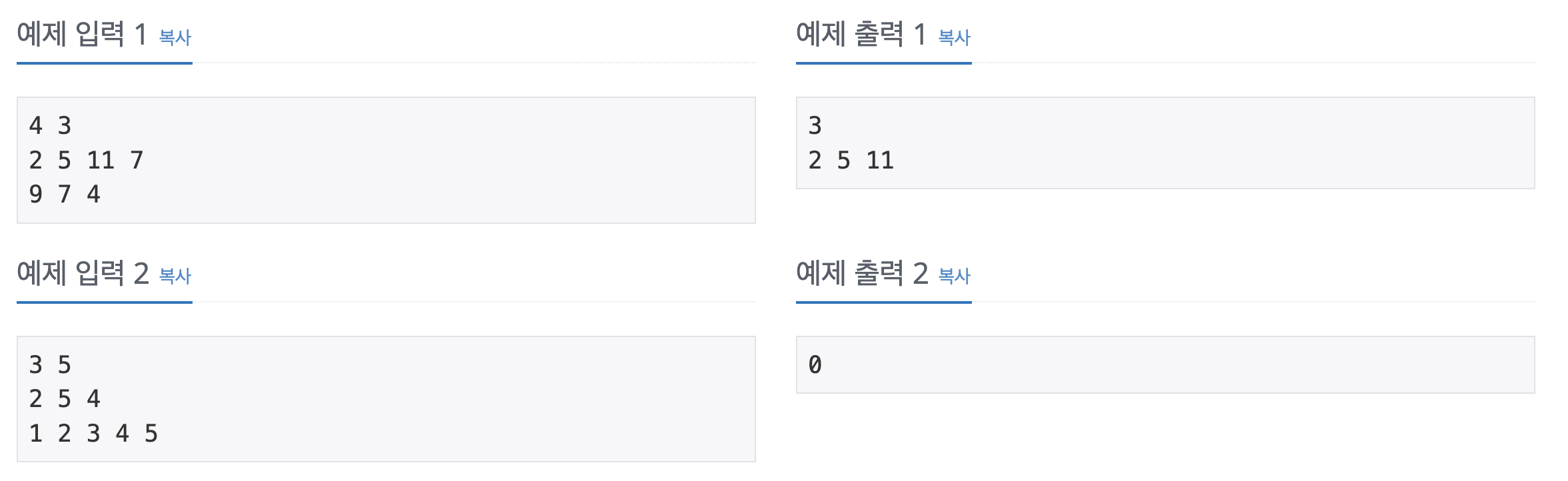
문제
몇 개의 자연수로 이루어진 두 집합 A와 B가 있다. 집합 A에는 속하면서 집합 B에는 속하지 않는 모든 원소를 구하는 프로그램을 작성하시오.
입력
첫째 줄에는 집합 A의 원소의 개수 n(A)와 집합 B의 원소의 개수 n(B)가 빈 칸을 사이에 두고 주어진다. (1 ≤ n(A), n(B) ≤ 500,000)이 주어진다. 둘째 줄에는 집합 A의 원소가, 셋째 줄에는 집합 B의 원소가 빈 칸을 사이에 두고 주어진다. 하나의 집합의 원소는 2,147,483,647 이하의 자연수이며, 하나의 집합에 속하는 모든 원소의 값은 다르다.
출력
첫째 줄에 집합 A에는 속하면서 집합 B에는 속하지 않는 원소의 개수를 출력한다. 다음 줄에는 구체적인 원소를 빈 칸을 사이에 두고 증가하는 순서로 출력한다. 집합 A에는 속하면서 집합 B에는 속하지 않는 원소가 없다면 첫째 줄에 0만을 출력하면 된다.
답안
import java.io.BufferedReader
import java.io.BufferedWriter
import java.io.InputStreamReader
import java.io.OutputStreamWriter
import java.util.StringTokenizer
fun main() {
val bufferedReader = BufferedReader(InputStreamReader(System.`in`))
val bufferedWriter = BufferedWriter(OutputStreamWriter(System.out))
val st = StringTokenizer(bufferedReader.readLine())
val nA = st.nextToken().toInt()
val nB = st.nextToken().toInt()
val setA = mutableSetOf<Int>()
val stA = StringTokenizer(bufferedReader.readLine())
repeat(nA) {
setA.add(stA.nextToken().toInt())
}
val setB = mutableSetOf<Int>()
val stB = StringTokenizer(bufferedReader.readLine())
repeat(nB) {
setB.add(stB.nextToken().toInt())
}
val result = setA.filter { it !in setB }.sorted()
bufferedWriter.write(result.size.toString() + "\n")
if (result.isNotEmpty()){
repeat(result.size){
bufferedWriter.write(result[it].toString() + " ")
}
}
bufferedReader.close()
bufferedWriter.flush()
}
풀이
세부 구현 방법
- 첫 줄을 읽어 집합 A와 B의 원소 개수(nA, nB)를 저장한다.
- 두 번째 줄에서 집합 A의 원소들을 읽어 mutableSetOf에 저장한다.
- 세 번째 줄에서 집합 B의 원소들을 읽어 mutableSetOf에 저장한다.
- setA에서 setB에 없는 원소만 필터링하여 result 리스트에 저장하고, 오름차순 정렬한다.
- 결과 리스트의 크기를 출력하고, 결과가 존재할 경우 원소들을 공백으로 구분하여 출력한다.
- 입출력 최적화를 위해 마지막에 bufferedWriter.flush()를 호출하고, bufferedReader.close()로 입력 스트림을 닫는다.
주의사항 및 성능 포인트
- 집합 A와 B 모두 원소가 최대 500,000개까지 주어질 수 있으므로,
빠른 원소 검색이 가능한 Set 자료구조를 사용해 O(1) 시간복잡도로 포함 여부를 체크했다. - 입력을 빠르게 처리하기 위해 BufferedReader와 StringTokenizer를 사용했다.
- filter + sorted를 통해 차집합을 구하고 오름차순 정렬했으며, 정렬은 O(N log N) 시간이 걸린다.
- 출력할 때 flush()를 마지막에 한 번만 호출하여 출력 성능을 최적화했다.
- 집합 A에는 속하지만 B에는 속하지 않는 원소가 없을 경우, 0만 출력하도록 조건문을 따로 처리했다.
기본 개념 정리
Set
- 중복을 허용하지 않는 자료구조이다.
- 하나의 값만 저장할 수 있으며, 같은 값이 또 들어오면 무시된다.
- 순서(인덱스 개념)가 없기 때문에 요소를 빠르게 찾는 데 최적화되어 있다.
- Kotlin에서 대표적으로 HashSet, LinkedHashSet, TreeSet 등이 있다.
- 요소 추가(add), 삭제(remove), 포함 여부 검사(contains)는 평균 O(1) (HashSet 기준).
- 정렬된 형태로 관리하고 싶으면 TreeSet을 사용한다 (이 경우 O(log N)).
val set = mutableSetOf(1, 2, 3)
set.add(4)
set.contains(2) // true
List
- 순서가 있는 자료구조이다.
- 인덱스를 기반으로 요소에 접근할 수 있다.
- 중복된 값도 허용된다.
- Kotlin에서는 ArrayList, MutableList, LinkedList 등이 있다.
- 인덱스 접근은 O(1) (ArrayList 기준).
- 요소 검색(contains)은 O(N) 시간이 걸린다.
- 순서를 유지하면서 데이터를 저장하고 다룰 때 사용한다.
👉 이 문제에서는 "중복이 없고, 빠른 포함 여부 검사"가 필요한 상황이므로 Set을 사용
- Set은 contains() 연산이 O(1) 로 매우 빠르다.
- List를 썼으면, A의 각 원소에 대해 B 전체를 O(N) 시간으로 검사해야 해서
시간 복잡도가 O(N^2) 가 되어 최대 500,000개 데이터에서는 시간 초과가 날 수도 있다.
'🌀알고리즘🌀' 카테고리의 다른 글
| [알고리즘] 동적 계획법(Dynamic Programming, DP) (0) | 2025.05.06 |
|---|---|
| [프로그래머스] 기능개발 (Kotlin) (0) | 2025.04.29 |
| [백준/10845] 큐 (Kotlin) (0) | 2025.04.28 |
| [백준/10828] 스택 (Kotlin) (0) | 2025.04.28 |
| [백준/15552] 빠른 A+B (Kotlin) (1) | 2025.04.28 |